How Developers Actually Use AI Coding Tools
Clustering 73,000 developers from JetBrains and Stack Overflow surveys
In February 2026, Claude Code accounted for 4% of all public GitHub commits---135,000 per day and doubling monthly. Meanwhile, 92.6% of developers now use an AI coding assistant at least monthly, but only 23% regularly use AI agents (tools that can both generate and execute code).
But what does “using AI tools” actually mean? A developer who accepts tab completions and one who delegates entire features to autonomous agents are both counted in the same adoption statistics. The variation in how developers use these tools is enormous---and mostly invisible in aggregate numbers.
This post uses real survey data to find natural groupings. I clustered 7,041 JetBrains respondents on 75 behavioral features (task frequency, delegation willingness, tool importance, and tool portfolio) and cross-validated against 30,816 Stack Overflow respondents. Then I compared my own Claude Code usage---192 sessions over 15 days---against the clusters that emerged.
The Productivity Paradox¶
Before the clusters, the headline finding from the research: there is a measurable gap between perceived and actual productivity gains from AI coding tools.
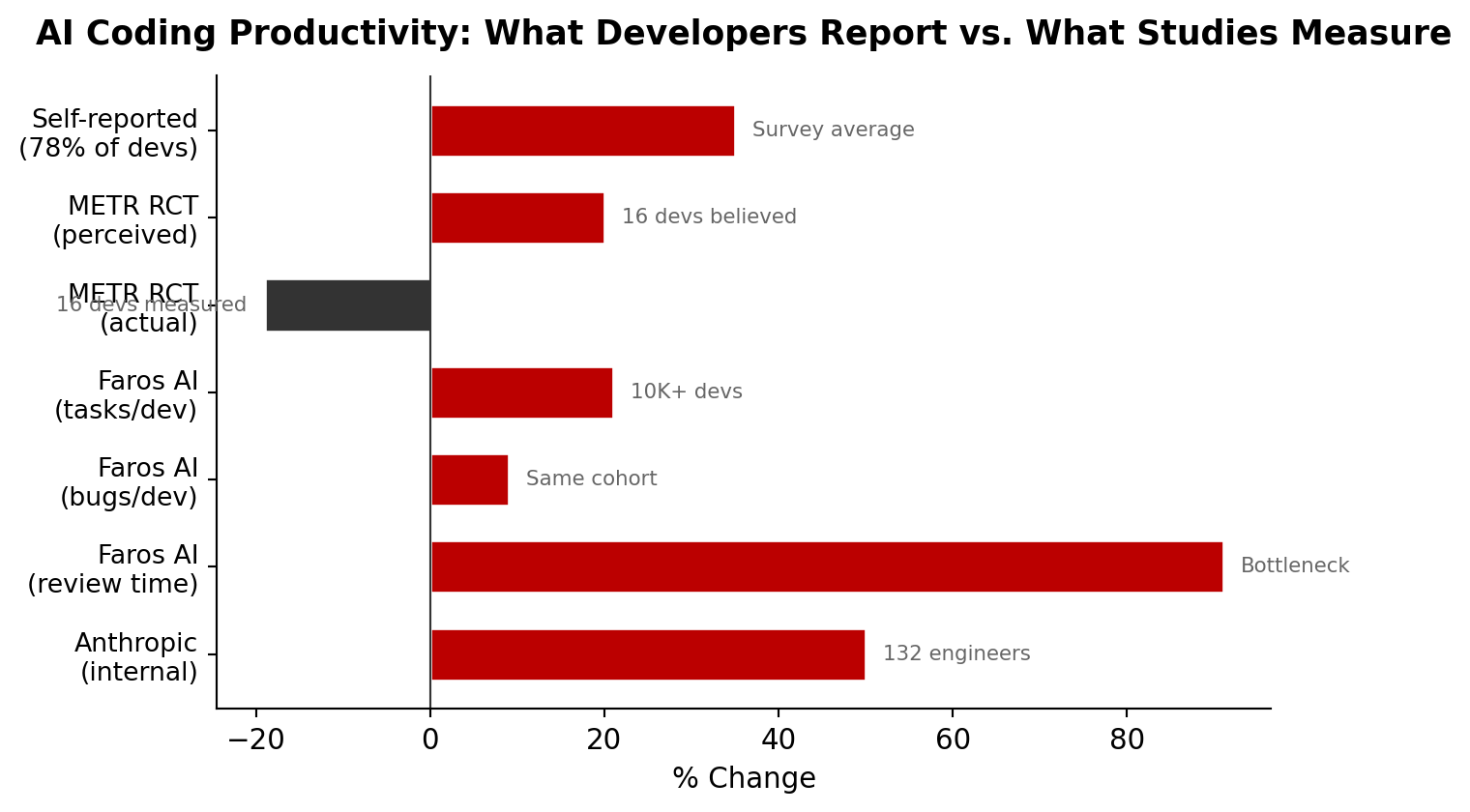
Figure 1:The perception-reality gap in AI coding productivity
The METR randomized controlled trial is particularly striking: experienced open-source developers believed they were 20% faster with AI, but were actually 19% slower. The Faros AI study of 10,000+ developers found individual output increased 21%, but review time ballooned 91% and bugs per developer rose 9%---yielding zero net organizational improvement. The self-reported 35% average gain comes from aggregate survey data across multiple studies; Anthropic’s internal figure of +50% is from their 132-engineer survey of 200K Claude Code transcripts.
This isn’t an argument against AI coding tools. It’s evidence that how you use them matters enormously. The clusters below show just how different those usage patterns are.
Methodology¶
Data Sources¶
| Dataset | N | Features | Role |
|---|---|---|---|
| JetBrains Dev Ecosystem 2025 | 7,041 | 75 behavioral | Primary clustering |
| Stack Overflow Dev Survey 2025 | 30,816 | 7 ordinal | Cross-validation |
| My Claude Code sessions | 192 | Session-level metrics | N=1 case study |
Clustering Pipeline¶
Feature engineering (JetBrains): 25 task frequency columns (ordinal 0--5: Never to Every day), 24 delegation willingness columns (ordinal 0--2: Myself/Unsure/Delegate), 16 importance columns (ordinal 0--3), tool count, 6 key tool binary flags, plus agent adoption intent, time saved, and AI sentiment. Total: 75 features.
Dimensionality reduction: StandardScaler → PCA retaining 90% variance → 59 components. t-SNE (perplexity=30) on PCA output for 2D visualization.
Clustering: K-means with k ∈ {3, 4, 5, 6, 7}. Best k selected by silhouette score. DBSCAN as sanity check.
Cross-validation: Same approach on Stack Overflow’s 7 core AI columns (usage frequency, sentiment, accuracy trust, complexity handling, job threat, agent usage, workflow change).
Limitations¶
JetBrains silhouette = 0.05. The clusters are not well-separated---survey respondents form a continuous distribution, not discrete groups. The clusters are useful as descriptive groupings, not rigid categories.
DBSCAN found 0 natural clusters (all 7,041 points classified as noise), confirming there are no dense, well-separated groups. K-means imposes structure that may not exist.
Stack Overflow’s simpler feature space (7 variables) produces cleaner clusters (silhouette = 0.22) but captures less behavioral nuance.
My personal data is N=1. The session metrics are real but not generalizable.
The JetBrains population skews toward JetBrains IDE users. Stack Overflow skews toward active community members. Neither is representative of all developers.
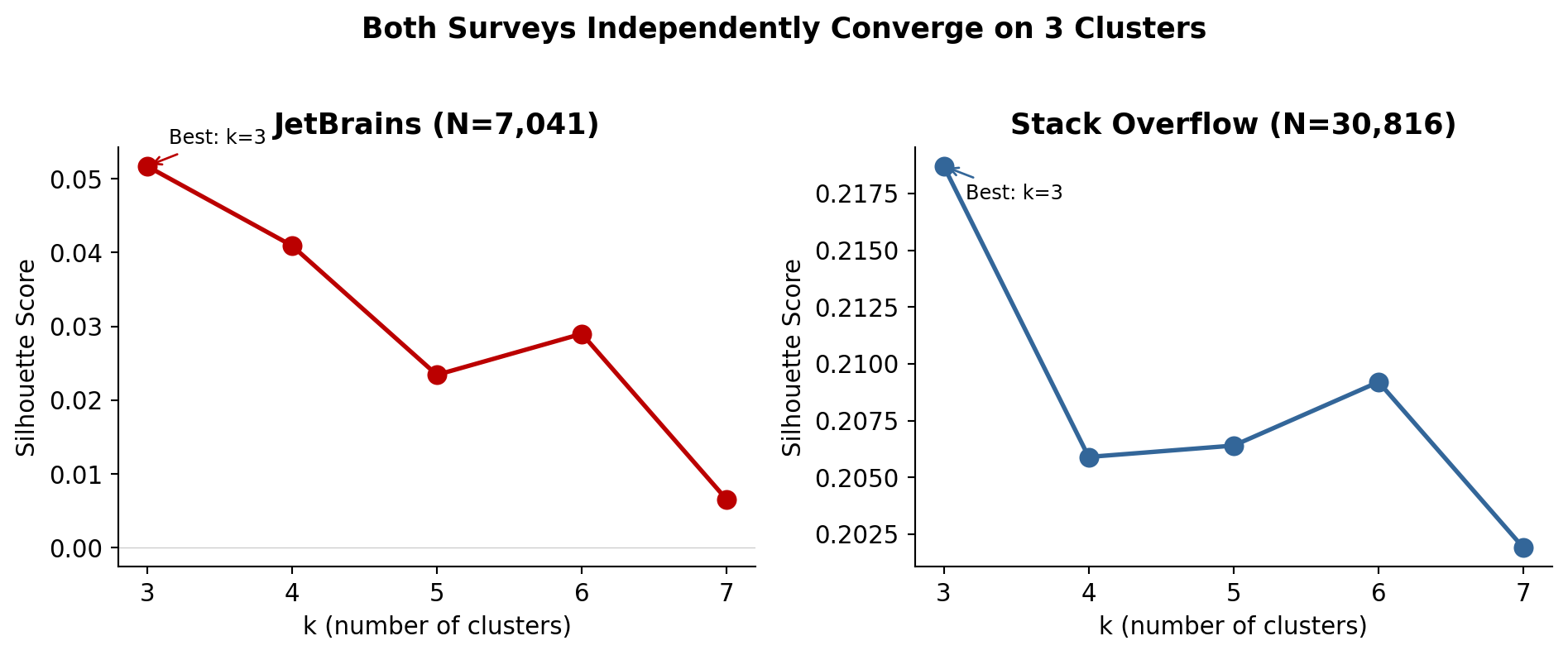
Figure 2:Silhouette scores across k values for both surveys
The Clusters¶
Three clusters emerged from the JetBrains data. Both surveys independently converged on k=3.
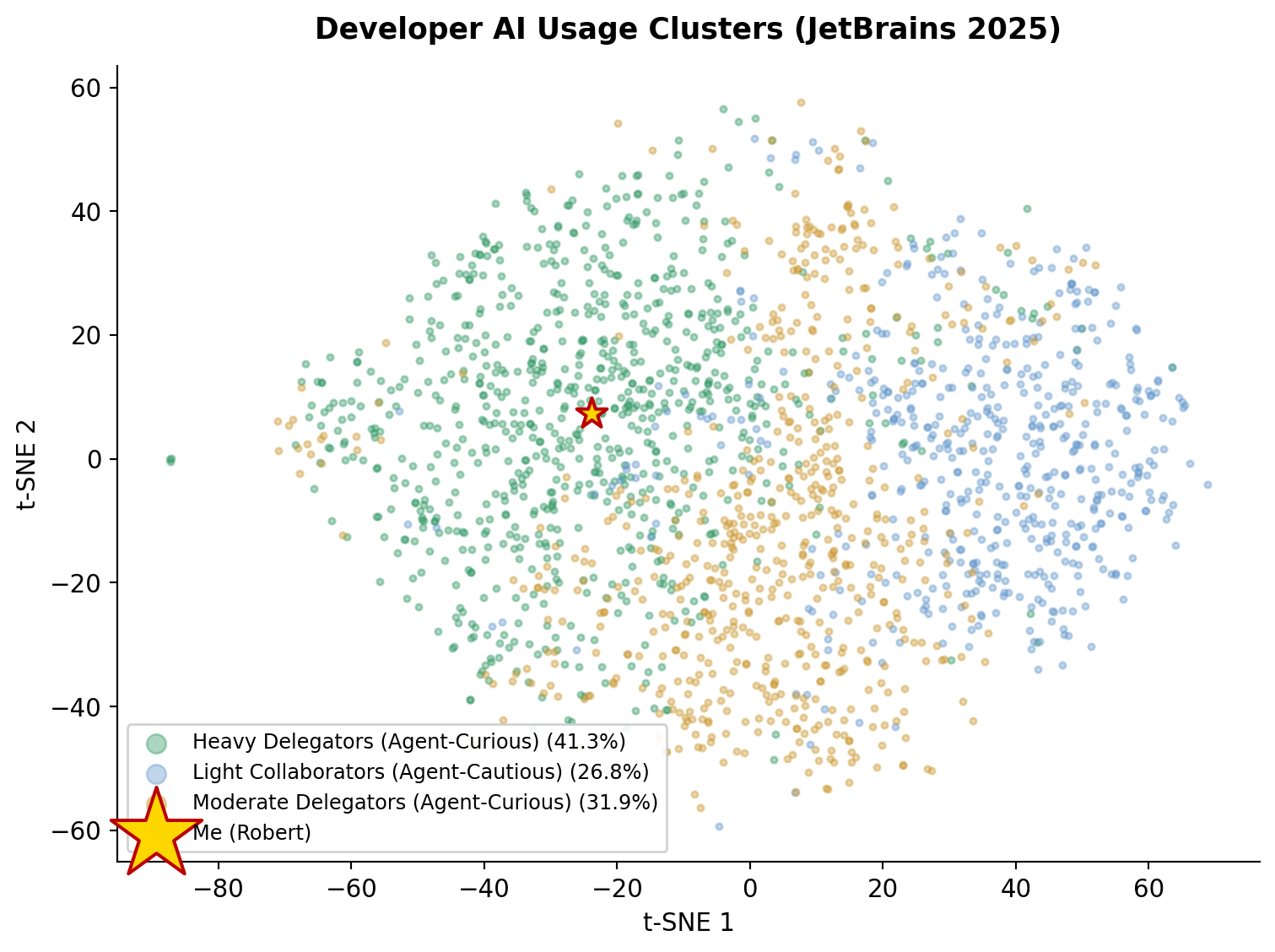
Figure 3:t-SNE projection of 7,041 JetBrains respondents, colored by cluster
Heavy Delegators (Agent-Curious)¶
2,910 respondents (41.3%) | Mean tools: 2.4 | Agent readiness: 3.8/5 | Time saved: 1.8/5
Most frequent AI tasks:
Asking questions about software development and coding: ███████████████████░ 4.8/5
Learning new things about coding and software development: ██████████████████░░ 4.7/5
Generating code: ██████████████████░░ 4.6/5
Code completion: ██████████████████░░ 4.6/5
Generating chunks of boilerplate, repetitive code: █████████████████░░░ 4.3/5
Tool mix: Chatgpt Web / Desktop / Mobile Apps (53.5%), Github Copilot (37.8%), Jetbrains Ai Assistant (23.4%), Cursor (19.3%), Anthropic Claude Code (6.7%)
AI sentiment: Hopeful (32.8%), Excited (29.8%), Anxious (15.0%)
Light Collaborators (Agent-Cautious)¶
1,884 respondents (26.8%) | Mean tools: 1.2 | Agent readiness: 2.9/5 | Time saved: 1.0/5
Most frequent AI tasks:
Asking questions about software development and coding: ████████████████░░░░ 4.2/5
Learning new things about coding and software development: ███████████████░░░░░ 4.0/5
Brainstorming new ideas: ████████████░░░░░░░░ 3.2/5
Explaining bugs and offering fixes for them: ████████████░░░░░░░░ 3.2/5
Improving or optimizing code: ████████████░░░░░░░░ 3.1/5
Tool mix: Chatgpt Web / Desktop / Mobile Apps (46.4%), Github Copilot (13.7%), Jetbrains Ai Assistant (9.3%), Cursor (2.1%), Anthropic Claude Code (1.6%)
AI sentiment: Uncertain (26.6%), Hopeful (23.9%), Anxious (17.2%)
Moderate Delegators (Agent-Curious)¶
2,247 respondents (31.9%) | Mean tools: 2.3 | Agent readiness: 3.6/5 | Time saved: 1.4/5
Most frequent AI tasks:
Asking questions about software development and coding: █████████████████░░░ 4.3/5
Code completion: █████████████████░░░ 4.3/5
Learning new things about coding and software development: ████████████████░░░░ 4.1/5
Generating code: ███████████████░░░░░ 3.9/5
Generating code comments or code documentation: ██████████████░░░░░░ 3.6/5
Tool mix: Github Copilot (57.7%), Chatgpt Web / Desktop / Mobile Apps (38.5%), Jetbrains Ai Assistant (30.5%), Cursor (11.6%), Anthropic Claude Code (5.5%)
AI sentiment: Hopeful (24.1%), Uncertain (23.4%), Anxious (21.7%)
Task Frequency Heatmap¶
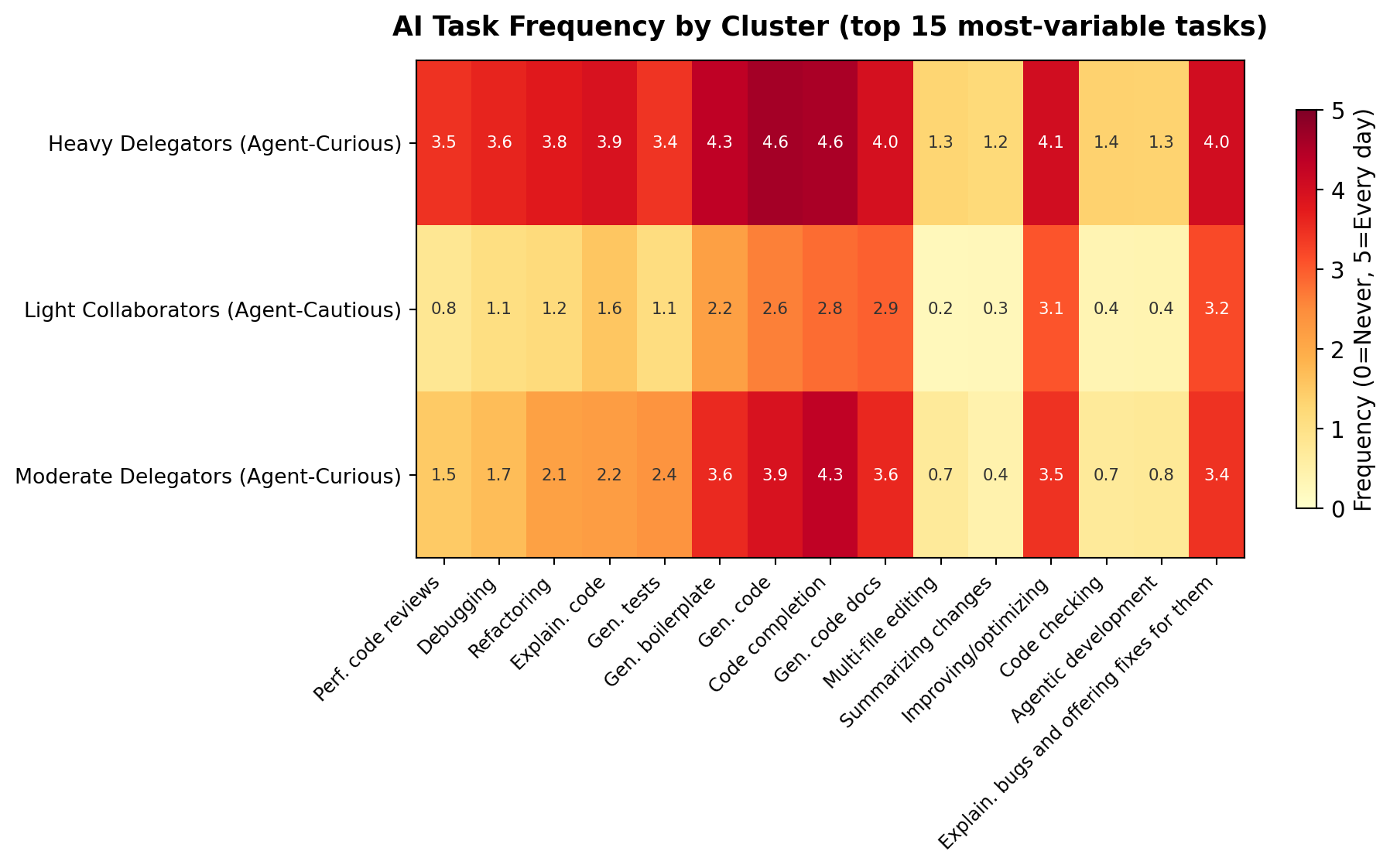
Figure 4:Mean AI task frequency by cluster (0=Never, 5=Every day)
Tool Composition¶
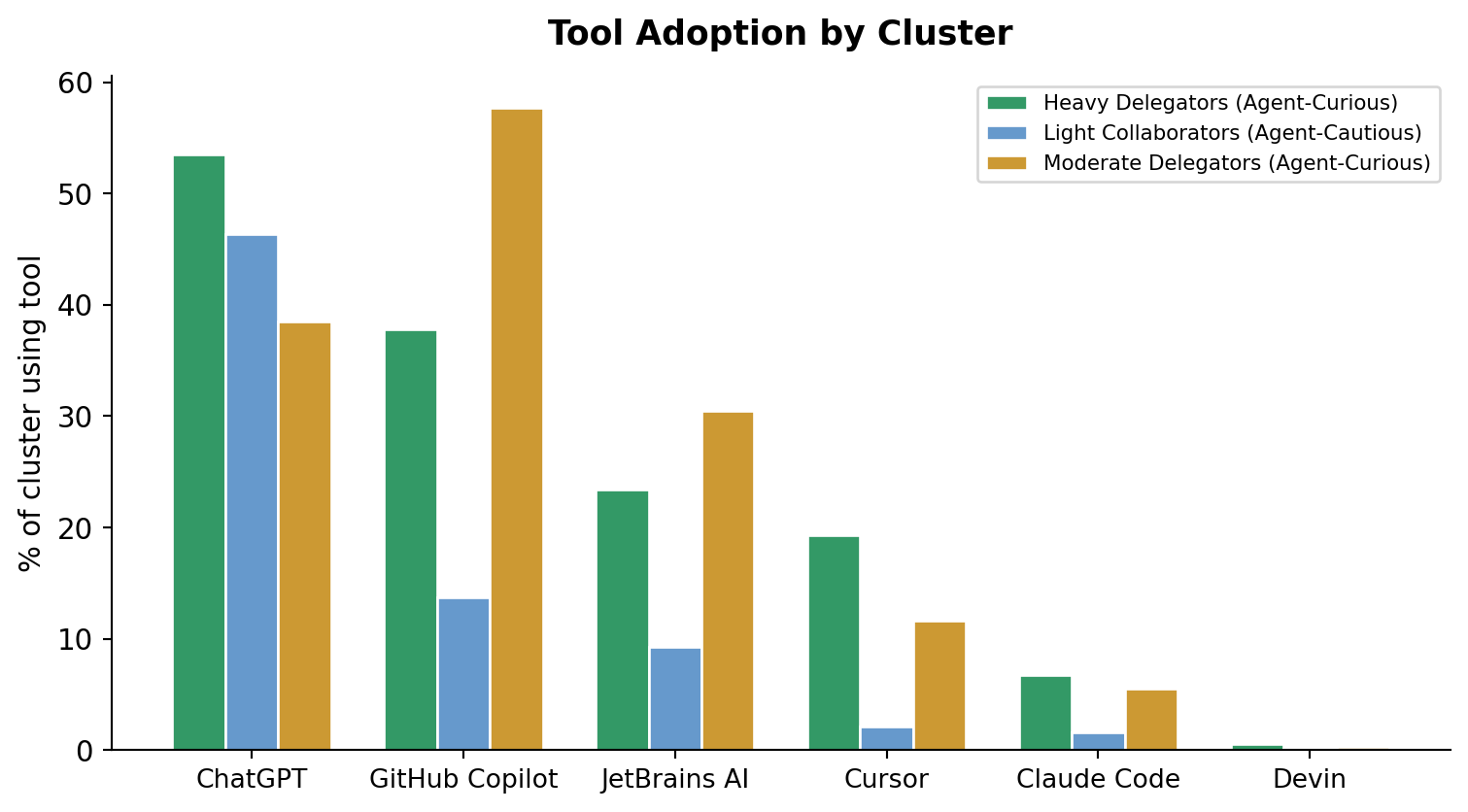
Figure 5:Tool adoption rates by cluster
Delegation Willingness¶
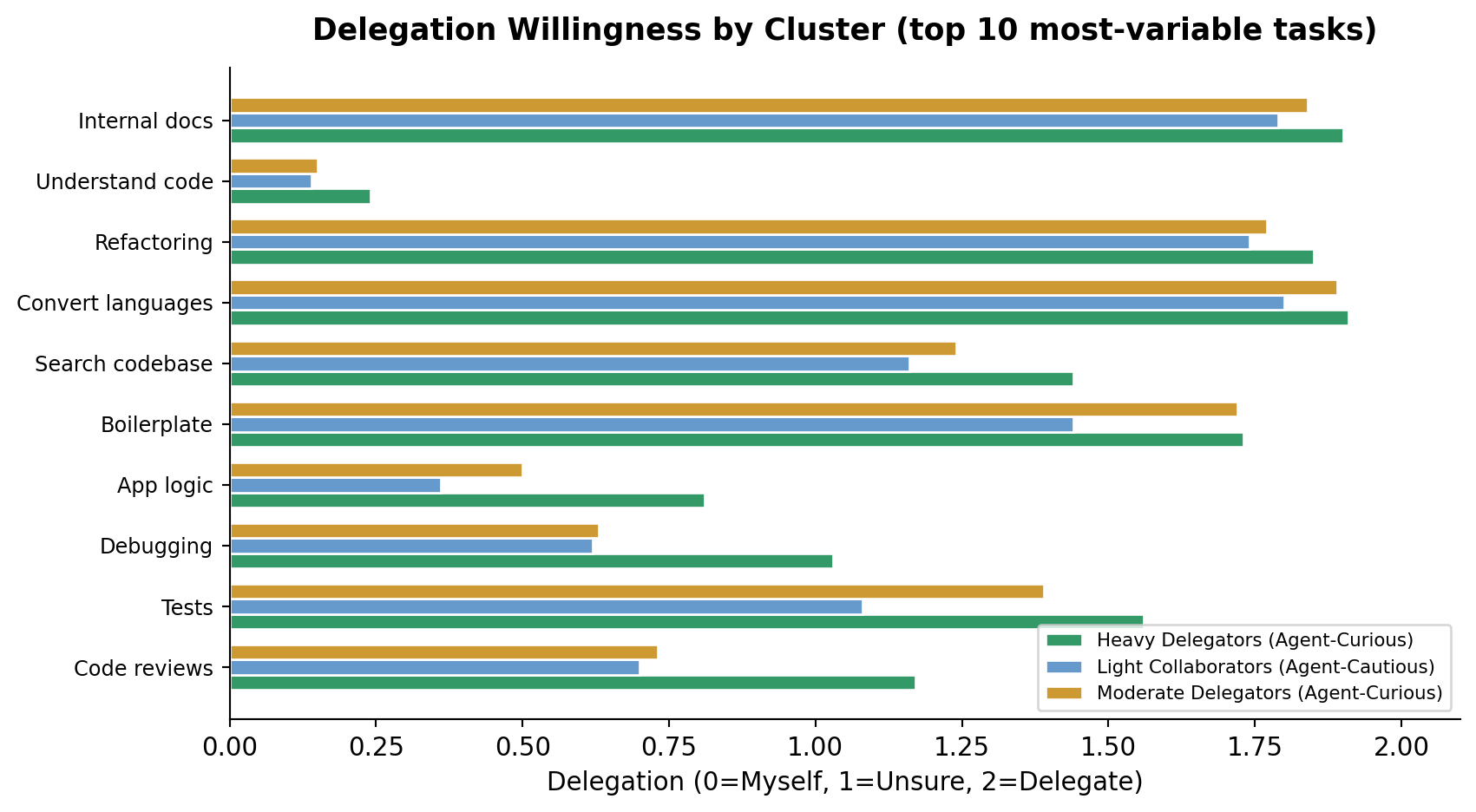
Figure 6:Mean delegation willingness by cluster (0=Do it myself, 2=Delegate to AI)
Agent Adoption & Time Saved¶
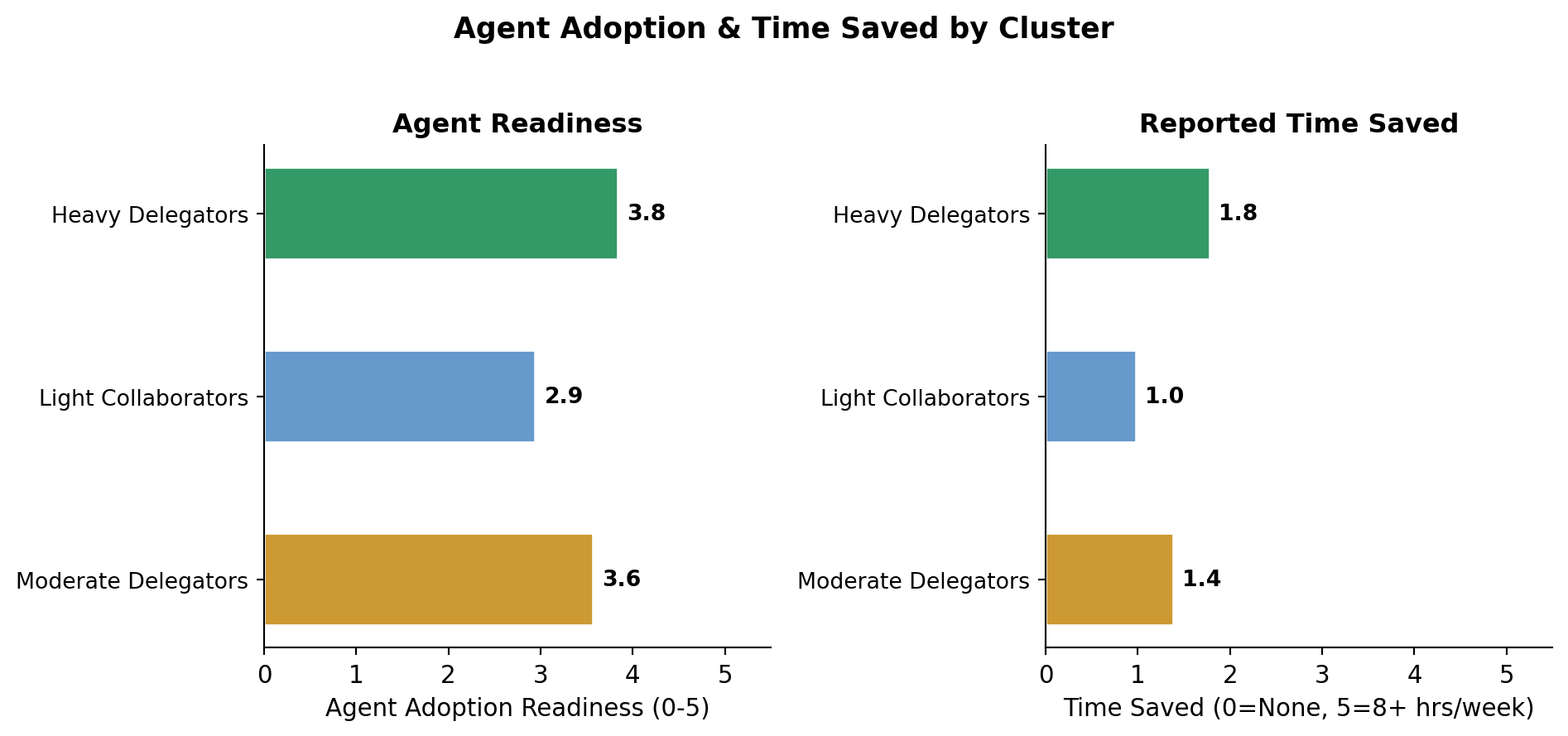
Figure 7:Agent adoption readiness and time saved per cluster
Claude Code Users¶
Of the 7,041 respondents, 348 use Claude Code. They cluster very differently from the general population.
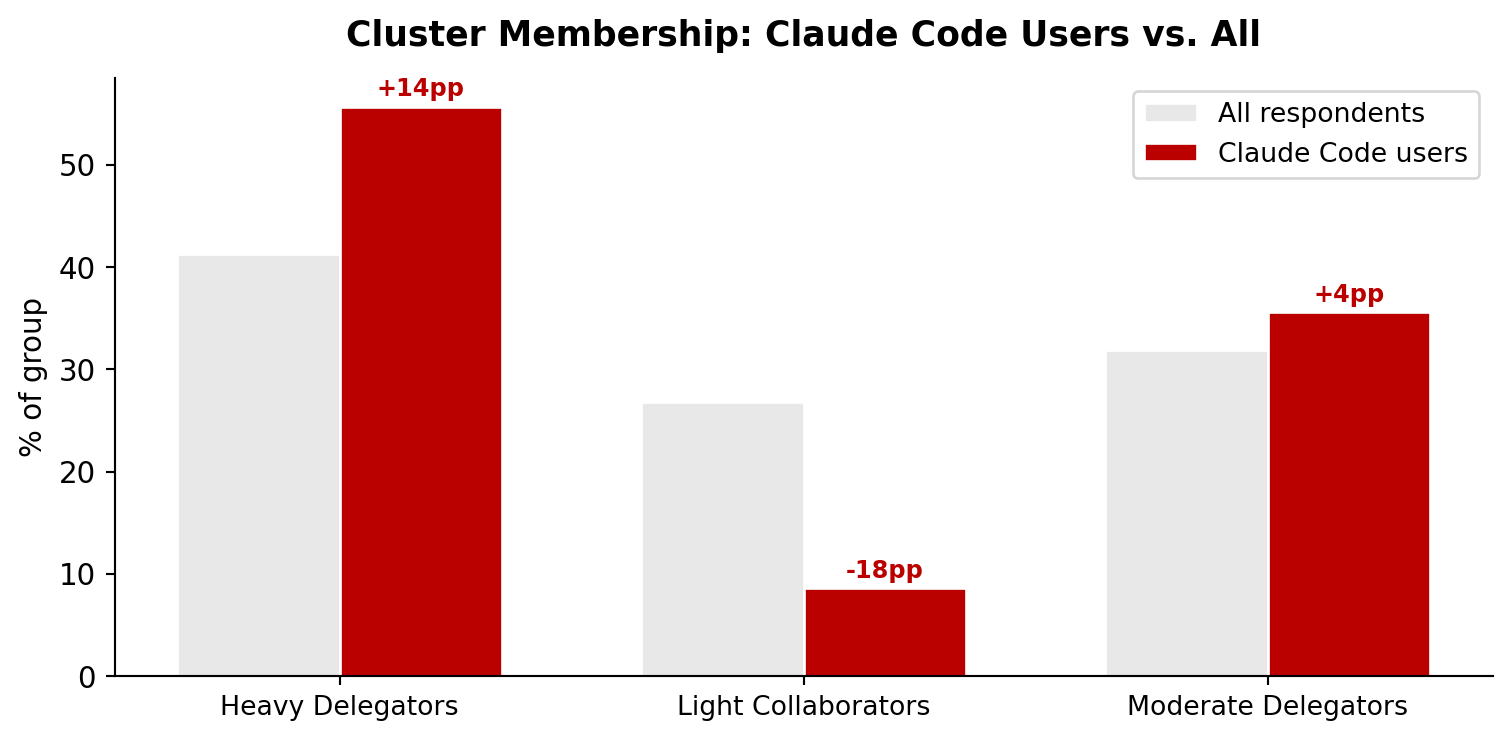
Figure 8:Claude Code users concentrate in the most active cluster
The difference is statistically significant (chi2=65.01, p<0.001, df=2).
Claude Code vs. Copilot vs. ChatGPT¶
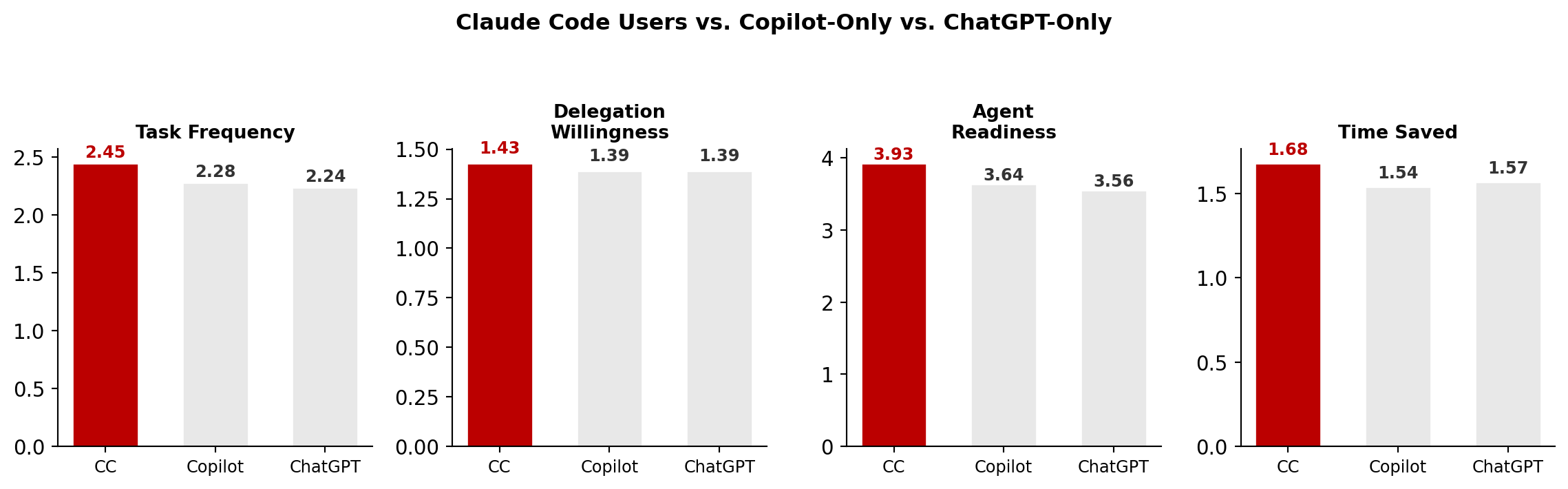
Figure 9:Claude Code users show higher task frequency, delegation, and agent readiness
Cross-Validation: Stack Overflow¶
The Stack Overflow survey asks different questions (sentiment, trust, complexity assessment) but independently produces the same structure: 3 clusters.
From 30,816 respondents with complete data (silhouette = 0.219):
| Cluster | Size | AI Usage | Sentiment | Agent Usage | Trust |
|---|---|---|---|---|---|
| AI Enthusiasts | 11,376 (36.9%) | daily | Very favorable | daily | Somewhat trust |
| AI Skeptics | 7,934 (25.7%) | No, and I don’t plan to | Very unfavorable | No, and I don’t plan to | Highly distrust |
| AI Enthusiasts | 11,506 (37.3%) | daily | Favorable | No, and I don’t plan to | Somewhat distrust |
The pattern across both surveys: a large group of active, enthusiastic adopters (~37--41%), a similar-sized group of moderate or cautious users (~32--37%), and a smaller group of skeptics or non-adopters (~26--29%). The same tripartite structure appears despite completely different question sets and populations.
Power Users in the Wild¶
The clusters above describe the population. But the most informative data points come from named practitioners who have documented their workflows in detail. Here’s how real power users map onto the spectrum.
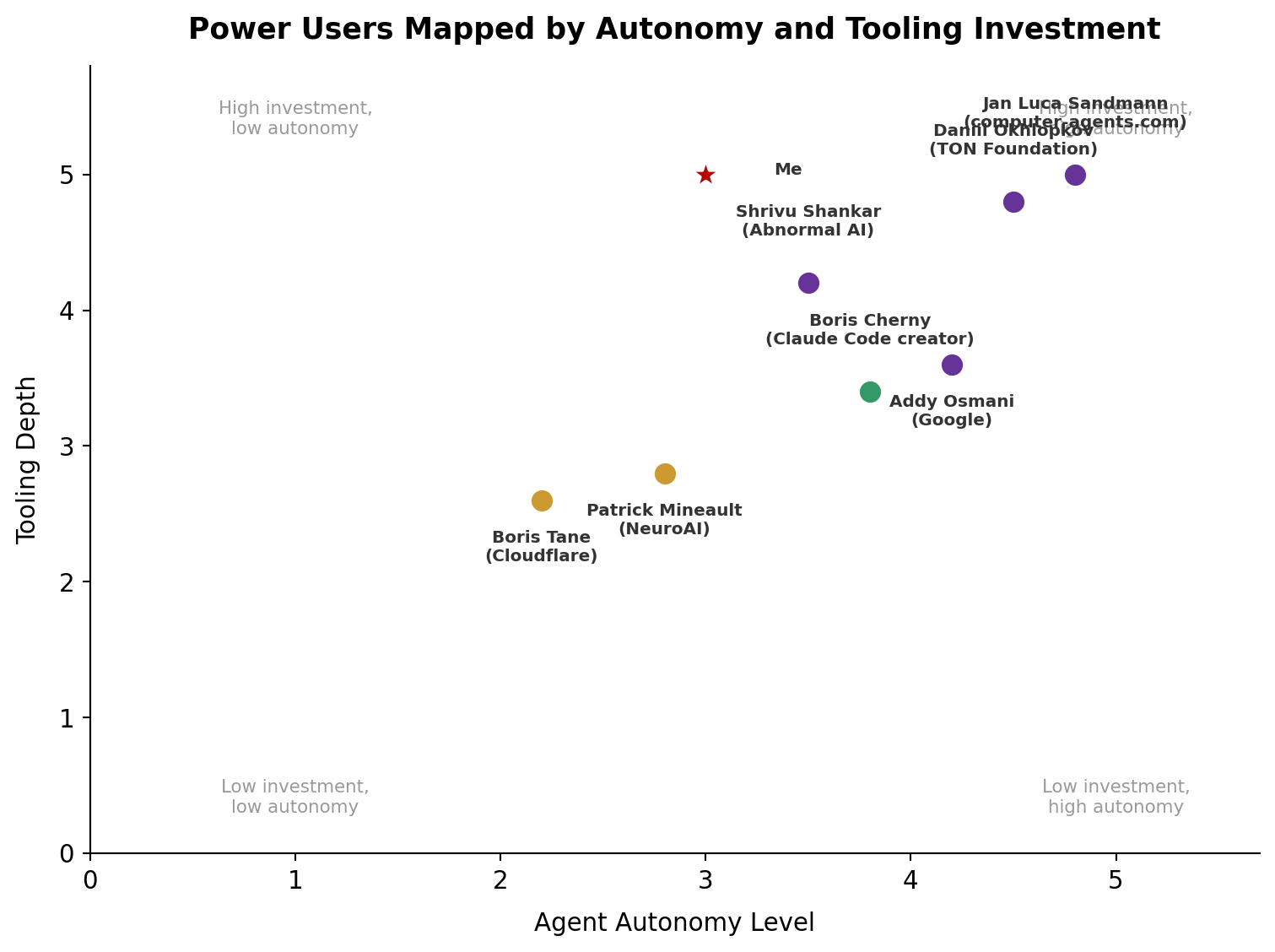
Figure 10:Named power users mapped onto the archetype spectrum
Boris Cherny (Claude Code’s creator) runs 5 local terminal sessions + 5--10 web sessions simultaneously, ships 20--30 PRs daily, and hasn’t manually edited code since November 2025. His setup is “surprisingly vanilla”---the key is plan mode first, then auto-accept, with verification loops that improve output 2--3x. In cluster terms, he would land squarely in the Heavy Delegators group, with the highest task frequency and delegation scores.
Boris Tane (Engineering Lead, Cloudflare) uses no hooks, skills, or MCP servers---pure workflow discipline. His Research-Plan-Annotate-Implement cycle involves 1--6 annotation rounds where he cherry-picks proposals before Claude writes a line of code. He represents the Moderate Delegators---high engagement but with deliberate human gatekeeping.
Shrivu Shankar (Abnormal AI) maintains a 13KB CLAUDE.md for their monorepo, uses block-at-submit hooks that force agents into test-fix loops before committing, and is migrating away from MCP servers toward CLI wrappers. His team consumes “several billion tokens monthly.”
Addy Osmani (Google) runs adversarial agent teams---competing hypothesis debuggers, parallel security/performance/test reviewers---treating agents like a distributed engineering team with shared task lists and inbox-based messaging.
Patrick Mineault (NeuroAI researcher) runs 5--10 parallel Claude windows, emphasizes “lots of plots” for cheap validation, and warns that AI tools “can produce wrong results faster than ever before”---making metacognition the critical skill for researchers.
Where I Land¶
Over 15 days in February--March 2026, I ran 192 sessions totaling 74 hours with Claude Code. The data comes from Claude Code’s session-meta JSON files, which log every tool call, token count, and timestamp.
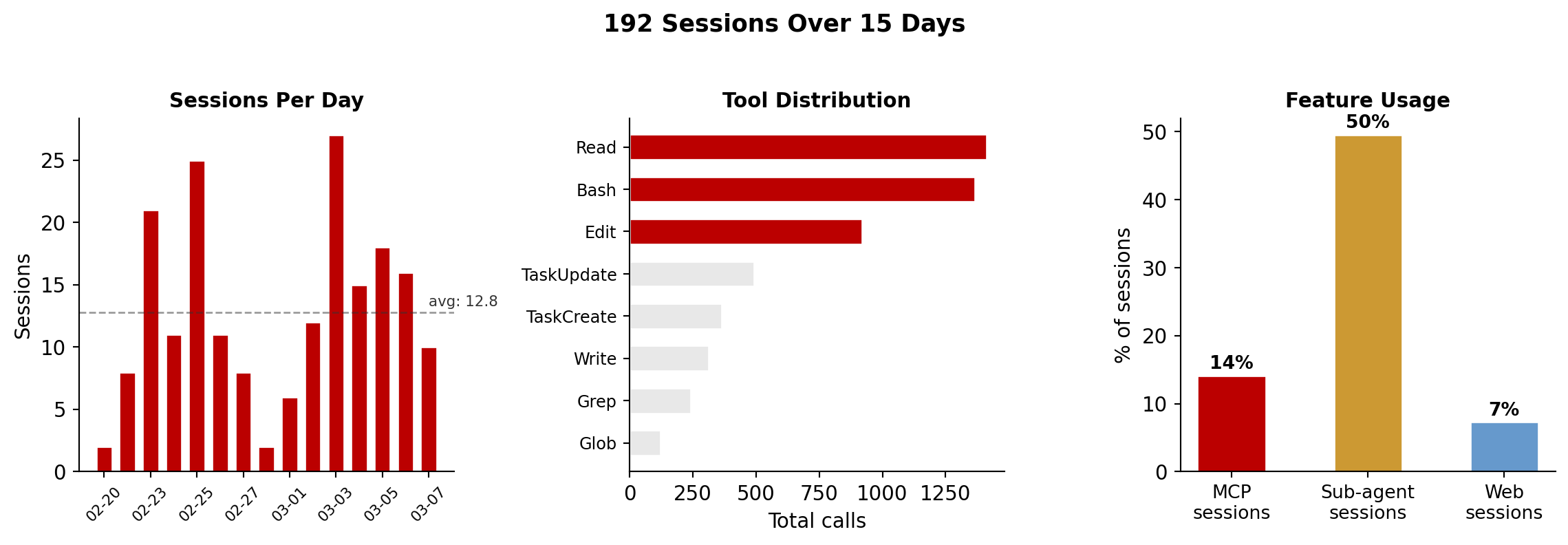
Figure 11:My Claude Code usage over 15 days
My projected cluster is Cluster 0 (Heavy Delegators (Agent-Curious))---the most active group. But the numbers reveal trade-offs:
Cost: 70/day average. The median Claude Code developer spends $6/day. I’m at 11.6x the median.
Intensity: 12.8 sessions/day, where the Max plan targets 4--5 hours of complex work daily.
Infrastructure: 6 MCP servers, 7 hooks, 15+ skills, 3 knowledge layers. This is not “just using Claude Code”---it’s building a platform on top of it.
What the numbers don’t show: Diminishing returns are real. Not every session was productive. The sub-agent sessions (42% of all sessions) often burned tokens on exploratory work that led nowhere. The hooks and skills took days to build and still require maintenance.
The honest assessment: I’m an outlier, and not all of that outlier status is productive. The infrastructure investment compounds across sessions, but only if the underlying projects benefit from cross-session memory and automated validation. For a single-project developer, most of this tooling would be overhead.
What Separates Effective Users¶
Across both the survey data and the practitioner reports, three patterns consistently separate developers who get compounding value from AI tools:
1. Verification as a first-class concern. The cluster with the highest task frequency (Heavy Delegators) also reports the most time saved---but only because they’ve built feedback loops. Boris Cherny calls verification loops the single most important practice: “Give Claude a way to verify its work... this can improve the quality of the final result by a factor of 2--3x.” Simon Willison’s Agentic Engineering Patterns makes the same point through TDD.
2. Persistent context across sessions. The biggest waste in AI coding is re-explaining project conventions every session. CLAUDE.md files, custom rules, knowledge graphs, and memory systems all address this. The JetBrains data shows that multi-tool users (cluster 0, avg 2.4 tools) report nearly twice the time savings of single-tool users (cluster 1, avg 1.2 tools). More tools means more persistent context, not just more features.
3. Separation of planning and implementation. Sessions that blend research, planning, and coding in a single context window tend to exhaust context before finishing. The most effective pattern: plan in session 1 (write a markdown artifact), review it yourself, implement in session 2 with the plan as input. Boris Tane’s 1--6 annotation cycles are an extreme version of this.
The Landscape Is Moving Fast¶

Figure 12:Key statistics about the current state of AI-assisted development
Card sources: adoption and agent usage from Stack Overflow 2025; code authorship share from GitHub telemetry and SemiAnalysis; commit volume from SemiAnalysis; perception/reality gap from METR RCT.
We’re in the early innings. Only 23% of developers use AI agents regularly, yet agents already author 4% of all GitHub commits. The gap between adoption of passive AI (autocomplete) and active AI (agents) will close rapidly as tools improve and verification patterns mature.
The question isn’t whether to use agentic coding tools. It’s whether you’re investing in the practices---especially verification---that separate compounding productivity from expensive churn.
Sources¶
Surveys and Studies¶
METR RCT Study --- 16 experienced developers, 246 tasks, randomized controlled trial
Faros AI Productivity Paradox --- 10,000+ developers, 1,255 teams
How AI is Transforming Work at Anthropic --- 132 engineers, 200K transcripts
Stack Overflow Developer Survey 2025 --- 49K+ responses, 30,816 clustered
JetBrains Developer Ecosystem 2025 --- 24,534 developers, 7,041 clustered
Agentic PRs on GitHub (arXiv 2509.14745) --- 567 PRs, 157 repositories
SemiAnalysis: Claude Code is the Inflection Point --- commit statistics, market analysis
Power User Workflows¶
Boris Cherny: Claude Code Creator Workflow --- plan mode, parallel sessions, verification loops
Boris Cherny interview (Pragmatic Engineer) --- 20--30 PRs/day, 100% AI-authored code, engineering productivity metrics
Boris Cherny workflow (InfoQ) --- verification loops improve output 2--3x
Boris Tane: How I Use Claude Code --- research-plan-annotate-implement methodology
Shrivu Shankar: How I Use Every Claude Code Feature --- enterprise CLAUDE.md, block-at-submit hooks, SDK usage
Daniil Okhlopkov: My Claude Code Setup --- MCP servers, custom skills, autonomous workflows
Addy Osmani: Claude Code Agent Teams --- adversarial agent patterns, parallel review
Patrick Mineault: Claude Code for Scientists --- academic research workflow, verification via plots
Jan Luca Sandmann: Claude Code to AI OS Blueprint --- 12 skills, 8 MCP servers, permanent agents
Patterns and Methodology¶
Simon Willison: Agentic Engineering Patterns --- TDD with agents, “writing code is cheap now”
HumanLayer: Writing a Good CLAUDE.md --- instruction limits, progressive disclosure
incident.io: Shipping Faster with Git Worktrees --- parallel development patterns
Panto AI: Vibe Coding Statistics --- code quality and churn metrics
GitHub Copilot Statistics --- acceptance rates, code generation share
Claude Code: Manage Costs --- per-developer cost benchmarks
Clustering¶
Data: JetBrains Dev Ecosystem 2025 raw data (download); Stack Overflow Dev Survey 2025 (download)
Method: K-means clustering on StandardScaler + PCA (90% variance) features, t-SNE for visualization. Code:
data/cluster_analysis.pyReproducibility: All clustering code is in the repository. Raw CSVs are .gitignore’d but freely downloadable from the links above.